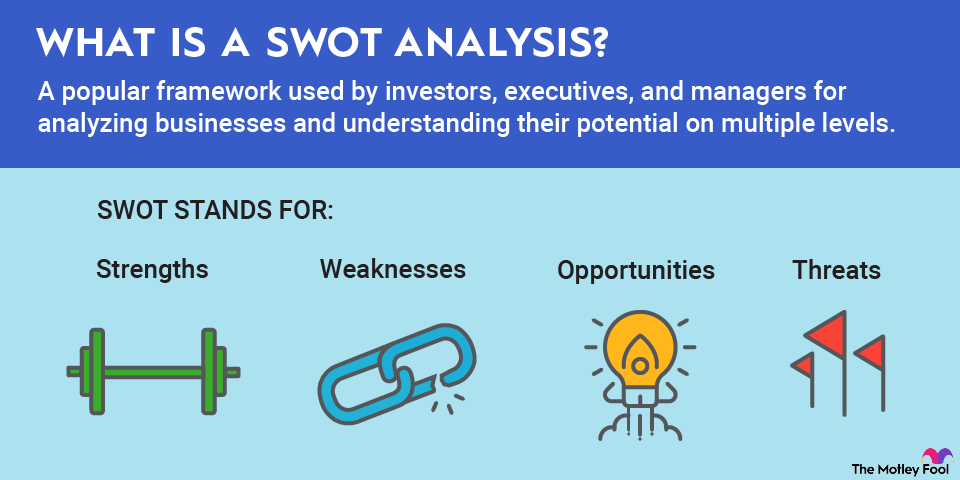
Loading paragraph...
Loading image...
Loading paragraph...
Loading definition...
Loading paragraph...
Loading paragraph...
Loading image...
Loading paragraph...
Loading hub_pages...
Loading paragraph...
About the Author

Anders Bylund is a contributing Motley Fool media and technology analyst covering semiconductors, cloud computing, internet infrastructure, quantum computing, and streaming media. Previously, Anders was a systems administrator for Nielsen Technology and CSX, gaining hands-on experience with enterprise-class systems. He was also a freelance writer for Ars Technica, TIME, USA Today, CNN, WIRED, and AOL's Daily Finance. He holds a bachelor’s degree in English and a master’s degree in library and information sciences from Florida State University. He believes in coyotes and time as an abstract.
Anders Bylund has no position in any of the stocks mentioned. The Motley Fool has positions in and recommends Meta Platforms. The Motley Fool has a disclosure policy.